Over the last few weeks, I’ve been working on a search engine for Fediverse instances!
The idea was to help new users, Facebook refugees, and Twitter rage-quitters find their ideal home on the fediverse. Fediverse instances are either for a wide audience or centered around a theme, a language, a hobby, or all of the above. The fediverse ecosystem has been growing like crazy - there are now close to 5000 instances with 4 million users. And finding an instance can be quite daunting.
While instances.social already has a great API and filtering mechanism, I wanted to build something more visual. I began by polling the original API to build a visual search feature using Lunr.js, but it has now become something bigger, thanks to feedback and support of the community.
Fediverse.to!
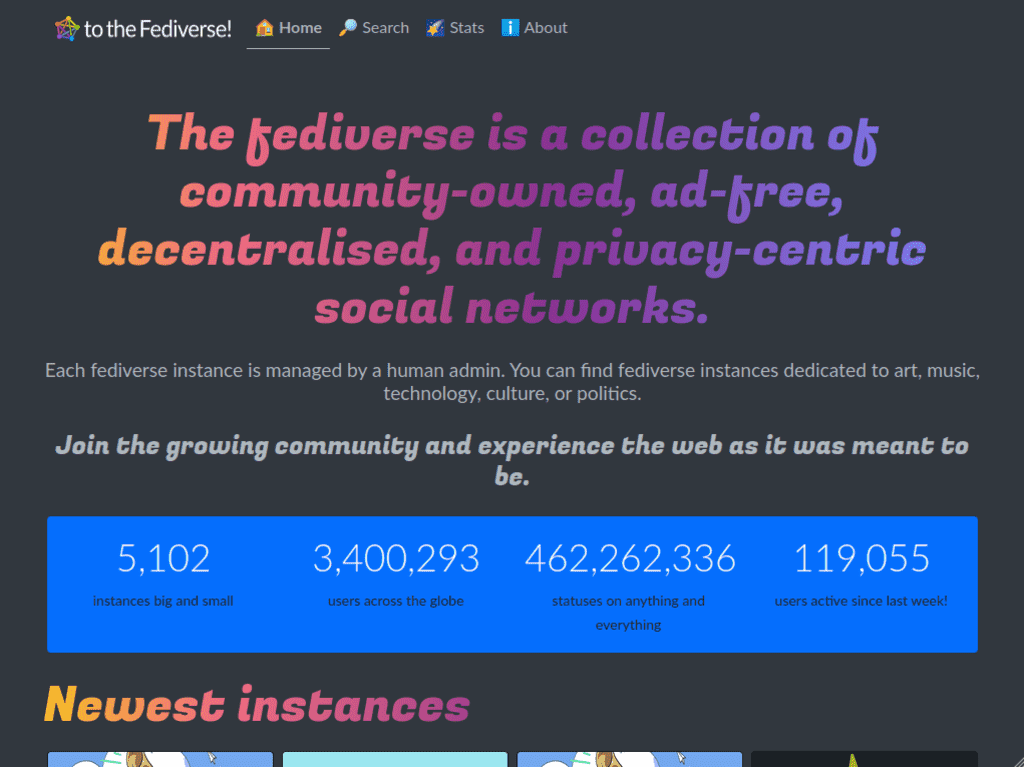
If you visit fediverse.to, you’ll see the new face of what was originally findmymastodon.com.
- The branding has changed - the site uses the fediverse logo (link to proposal).
- The home page now has a larger selection of instances for new users to choose from, with dedicated sections for some languages and categories.
- Every instance now has its own dedicated page which, at the moment, shows basic statistics about that instance.
- The home page shows newest instances at the top to support new members of the federation.
Apart from the above, the original features are still there:
- Support for light and dark theme.
- Display total users, total status updates, and weekly active users for all instances.
- Display description, language, categories, and prohibited content settings for all instances.
- The search features allows searching for specific text in instance names and descriptions.
- Filtering by language, category, content blocks, minimum users, and maximum users is supported.
- The website visitor stats are public thanks to Plausible.
- The website is still an open-source static website deployed using Netlify.
A new engine under the hood
Under the hood, though, is where the real changes have happened.
Originally, I was using a small Python script to scrape the main API and generate a Lunr search index. The front-end website would then use JavaScript, Bootstrap, and Lunr to display visual cards for search results. There was also a basic filtering mechanism to mirror the original instances.social API which still exists.
Now fediverse.to uses a Django + PostgreSQL back-end to dynamically generate Jekyll pages for each instance.
First, the API is used to fetch a list of instances. Then Django visits each instance’s metadata URL and pulls its information and the list of domains it peers with. The process is then repeated for all the peers. This way I can be certain I’m not missing any instance in the network. Once this process completes, Django generates a Jekyll page for each instance.
For example, if you browse Mastodon.social’s Jekyll page, you’ll see the following:
layout: instance
page: /
name: "mastodon.social"
instance_url: "mastodon.social"
short_description: "Server run by the main developers of the project It is not focused on any particular niche interest - everyone is welcome as long as you follow our code of conduct!..."
description: "Server run by the main developers of the project It is not focused on any particular niche interest - everyone is welcome as long as you follow our code of conduct!"
admin: "staff@mastodon.social"
admin_email: "staff@mastodon.social"
statuses: 32950135
active_users: 599995
users: 599995
statuses_display: "33M"
active_users_display: "600k"
users_display: "600k"
languages: en
categories:
thumbnail: "files.mastodon.social/site_uploads/files/000/000/001/original/vlcsnap-2018-08-27-16h43m11s127.png"
registrations: True
approval_required: False
version: "3.4.3"
created_at: 1638080432.0
Future plans
The idea behind generating a separate page for each instance is simple - it allows the site to grow! I’m planning to add the following features soon:
- Use D3 to show the entire fediverse network using network/peer visualizations.
- Add more information for each instance, such as the fediverse software its running (Mastodon/Misskey/etc) and the country its hosted in.
- Parse the instance domain for country information, such as
.deand.fr, and categories, such as.techand.art. - Parse the instance descriptions for country and category information.
- Build an API for other users and admins to scrape.
- Host everything on a remote server and automate content updates using
cronjobordjango-crons.
Eventually I’m hoping fediverse.to can become its own data source and the de-facto directory for the new internet - but that’s still a long way off :)
Work to be done
Aside from new features, there’s still work to be done to make fediverse.to fully functional.
The search feature currently has some bugs to iron out. I’m still working on the new back-end to generate the Lunr search index. I debated whether or not to release the site in its current state, but the earlier I get feedback the better the site will be. I’m hoping all of you will bear with me just a little while longer.
Stay tuned!
Anyhoo. That’s the general plan. fediverse.to is my first open-source project so I’m learning as I go along. But you’ve all been very supportive with ideas and feedback and I’m already excited about version 2.0!
So wish me luck… and stay tuned for more! I’ll post future updates here, so follow me using the link on the, erm, top right?
And before I forget… spread the word!
Thanks, Ayush.