For some time now I’ve been looking for a resource for complete monitoring of Nginx. I’m putting together what I’ve figured out in this note. You may want to look at some of my previous notes on this subject to get a better understanding of what I’m about to do. Links to those notes are in the resources section at the end of this note.
Goals
The goal for this exercise is very simple. We want to gather and monitor the following metrics:
- System CPU metrics, including
idle,interrupt,nice,softirq,steal,system,user, andwait. - System load metrics with average loads of 1 minute, 5 minutes, and 15 minutes.
- System memory metrics, including
buffered,cached,free,slab_recl,slab_unrecl, andused. We need absolute values in bytes as well as percentages of total. - Nginx metrics, including
acceptedconnections,handledconnections,activeconnections,readingconnections,waitingconnections,writingconnections, and total request count. - Nginx response HTTP status codes for 2XX, 3XX, 4XX and 5XX.
The way we’ll be doing this is by setting up Collectd to gather the above metrics and put them into InfluxDB. We’ll also set up Grafana to read those metrics from InfluxDB and render graphs and dashboards from it. For this exercise, we’ll install InfluxDB and Grafana locally on the same machine, but I recommend you move that setup to a different machine or cluster for production use.
Prerequisites
We need only one thing for this exercise. We need an Ubuntu 16.04 machine with Nginx installed and running.
If you have the prerequisites in place, let’s get started.
Step 1: Configuring Nginx
We need to configure Nginx to handle the 4th and 5th goals mentioned above. For the 4th we’ll have to enable the stubs_status module. For the 5th we’ll have to read the access logs process them.
We need to check if our Nginx installation has the stubs_status module enabled. We can check that using the command below:
nginx -V 2>&1 | grep -q with-http_stub_status && echo OK
If we get OK, then the module is installed, and we can proceed. Add the configuration below to /etc/nginx/sites-enabled/default inside the server section:
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
Save the file, and reload Nginx using service nginx reload. Let’s see if this is working. Issue the CURL command below, and you should see something like this:
curl http://localhost/nginx_status
Active connections: 1
server accepts handled requests
1 1 1
Reading: 0 Writing: 1 Waiting: 0
We’ll read this endpoint in Collectd to accomplish goal number 4.
Next, Nginx logs will need to be configured so we can read them properly for our metrics. Add/update the following in /etc/nginx/nginx.conf.
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'http_code:$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" '
'request_time:$request_time $request_length $bytes_sent';
access_log /var/log/nginx/access.log main;
Once that’s done, reload Nginx and we should start seeing logs like this in /var/log/nginx/access.log:
103.X.X.X - - [30/Aug/2017:19:06:13 +0000] "GET / HTTP/1.1" http_code:304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36" request_time:0.000 497 189
Note the number after http_code:. This is the HTTP status code for this request. Also note the number after request_time:. This is the time it took Nginx to process this request in seconds. We’ve added the special string before the colon so we can grep it in Collectd using regular expressions. This will help us accomplish goal number 5.
Step 2: Configuring InfluxDB
Let’s install InfluxDB on the same box so we can have Collectd write its gathered metrics there. Run the following commands:
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
sudo apt-get update && sudo apt-get install influxdb
sudo service influxdb start
In my case, the above commands will install InfluxDB version 1.3.5. Once the installation completes, hit influx at the command-line and press Enter, and it will drop you to the InfluxDB shell. We will use this shell to create a database we’ll use to collect our metrics from Collectd. Enter the following command:
Connected to http://localhost:8086 version 1.3.5
InfluxDB shell version: 1.3.5
> CREATE DATABASE collectd_metrics
>
If the command ran fine, there should be no output. Check if your database was created by running the following command:
> SHOW DATABASES
name: databases
name
----
_internal
collectd_metrics
Next, let’s configure InfluxDB to listen to data from Collectd. Update /etc/influxdb/influxdb.conf, and find the [[collectd]] section. Under this section, add the following configuration:
[[collectd]]
enabled = true
bind-address = ":25826"
database = "collectd_metrics"
retention-policy = ""
batch-size = 5000
batch-pending = 10
batch-timeout = "10s"
read-buffer = 0
typesdb = "/usr/share/collectd/types.db"
Save the file, and restart InfluxDB:
service influxdb restart
Step 3: Configuring Collectd
With InfluxDB running and configured to handle data from Collectd, we can now set it up. But before we can configure Collectd, we need to install it. That can be done using the following commands:
add-apt-repository ppa:collectd/collectd-5.5
apt-get update
apt-get install collectd
Next, update /etc/collectd/collectd.conf and add the configuration below.
Hostname "localhost"
FQDNLookup false
BaseDir "/var/lib/collectd"
PluginDir "/usr/lib/collectd"
TypesDB "/usr/share/collectd/types.db"
AutoLoadPlugin true
Interval 1
MaxReadInterval 10
Timeout 2
ReadThreads 5
WriteThreads 5
<Plugin "logfile">
LogLevel "info"
File "/var/log/collectd.log"
Timestamp true
</Plugin>
<Plugin "tail">
<File "/var/log/nginx/access.log">
Instance "nginx"
<Match>
Regex "http_code:2[0-9]{2}"
DSType "CounterInc"
Type "counter"
Instance "http_2xx"
</Match>
<Match>
Regex "http_code:3[0-9]{2}"
DSType "CounterInc"
Type "counter"
Instance "http_3xx"
</Match>
<Match>
Regex "http_code:4[0-9]{2}"
DSType "CounterInc"
Type "counter"
Instance "http_4xx"
</Match>
<Match>
Regex "http_code:5[0-9]{2}"
DSType "CounterInc"
Type "counter"
Instance "http_5xx"
</Match>
<Match>
Regex "request_time:([\.0-9]*)"
DSType "GaugeAverage"
Type "delay"
Instance "rt_seconds"
</Match>
</File>
</Plugin>
<Plugin "cpu">
ReportByState true
ReportByCpu true
ValuesPercentage true
</Plugin>
<Plugin "memory">
ValuesAbsolute true
ValuesPercentage true
</Plugin>
<Plugin "load">
ReportRelative false
</Plugin>
<Plugin "network">
Server "localhost"
</Plugin>
<Plugin "nginx">
URL "http://localhost/nginx_status"
</Plugin>
The above Collectd configuration will collect all the metrics we have in our goal list and store it in InfluxDB. Let’s restart Collectd:
service collectd restart
Check out /var/log/collectd.log, and you should start seeing something like this:
[2017-08-31 08:03:13] supervised by systemd, will signal readyness
[2017-08-31 08:03:13] Initialization complete, entering read-loop.
Step 4: Verifying Our Setup
Let’s drop back to the InfluxDB console by hitting influx on the command-line. We need to verify if our database is getting data from Collectd.
First, we need to see what measurements are now available in our InfluxDB database. You can see that by entering the following commands:
> USE collectd_metrics
Using database collectd_metrics
> SHOW MEASUREMENTS
name: measurements
name
----
cpu_value
load_longterm
load_midterm
load_shortterm
memory_value
nginx_value
tail_value
As you can see, the measurements for all the plugins we defined in our Collectd configuration have begun sending data to our database. Let’s explore some of the data present in these measurements.
> SELECT * FROM cpu_value LIMIT 5
name: cpu_value
time host instance type type_instance value
---- ---- -------- ---- ------------- -----
1504166594674943356 localhost 0 percent user 0
1504166594674944551 localhost 0 percent system 0
1504166594674945186 localhost 0 percent wait 0
1504166594674946088 localhost 0 percent nice 0
1504166594674947735 localhost 0 percent interrupt 0
> SELECT * FROM load_longterm LIMIT 5
name: load_longterm
time host type value
---- ---- ---- -----
1504166593676326360 localhost load 0.01
1504166594675157919 localhost load 0.01
1504166595674935918 localhost load 0.01
1504166596674937814 localhost load 0.01
1504166597674936489 localhost load 0.01
> SELECT * FROM load_midterm LIMIT 5
name: load_midterm
time host type value
---- ---- ---- -----
1504166593676326360 localhost load 0.03
1504166594675157919 localhost load 0.03
1504166595674935918 localhost load 0.03
1504166596674937814 localhost load 0.03
1504166597674936489 localhost load 0.03
> SELECT * FROM load_shortterm LIMIT 5
name: load_shortterm
time host type value
---- ---- ---- -----
1504166593676326360 localhost load 0.04
1504166594675157919 localhost load 0.04
1504166595674935918 localhost load 0.04
1504166596674937814 localhost load 0.04
1504166597674936489 localhost load 0.04
> SELECT * FROM memory_value LIMIT 5
name: memory_value
time host type type_instance value
---- ---- ---- ------------- -----
1504166593676266241 localhost memory buffered 140206080
1504166593676266241 localhost percent used 2.088227508421528
1504166593676266241 localhost memory free 1918234624
1504166593676266241 localhost percent buffered 3.5533917087526796
1504166593676266241 localhost memory used 82395136
> SELECT * FROM tail_value LIMIT 5
name: tail_value
time host instance type type_instance value
---- ---- -------- ---- ------------- -----
1504166593676347922 localhost nginx counter http_2xx 0
1504166593676348760 localhost nginx counter http_3xx 0
1504166593676349378 localhost nginx counter http_4xx 0
1504166593676349935 localhost nginx counter http_5xx 0
1504166594676475033 localhost nginx counter http_2xx 0
> SELECT * FROM tail_value WHERE type_instance = 'rt_seconds'
name: tail_value
time host instance type type_instance value
---- ---- -------- ---- ------------- -----
1504174411824482217 localhost nginx delay rt_seconds 0
1504174413824214049 localhost nginx delay rt_seconds 0
1504175457618828884 localhost nginx delay rt_seconds 0.413
1504175460618703877 localhost nginx delay rt_seconds 0.62
1504175670607922976 localhost nginx delay rt_seconds 0.252
> SELECT * FROM nginx_value LIMIT 5
name: nginx_value
time host type type_instance value
---- ---- ---- ------------- -----
1504168639604245332 localhost nginx_connections active 1
1504168639604265171 localhost connections accepted 2
1504168639604272880 localhost connections handled 2
1504168639604278021 localhost nginx_requests 2
1504168639604284828 localhost nginx_connections reading 0
The machine I’m setting this up on is extremely under-utilised right now, so the number might not be realistic. But its enough to demonstrate how to set this all up.
Note the type and type_instance fields in the tables. They are both tags, meaning they’re used to label the data inserted in the database. type is a higher level category that may or may not contain many type_instance tags. In order to see how many distinct pairs of these two exist, there is a very helpful InfluxDB command you can use:
> SHOW SERIES
key
---
cpu_value,host=localhost,instance=0,type=percent,type_instance=idle
cpu_value,host=localhost,instance=0,type=percent,type_instance=interrupt
cpu_value,host=localhost,instance=0,type=percent,type_instance=nice
cpu_value,host=localhost,instance=0,type=percent,type_instance=softirq
cpu_value,host=localhost,instance=0,type=percent,type_instance=steal
cpu_value,host=localhost,instance=0,type=percent,type_instance=system
cpu_value,host=localhost,instance=0,type=percent,type_instance=user
cpu_value,host=localhost,instance=0,type=percent,type_instance=wait
cpu_value,host=localhost,instance=1,type=percent,type_instance=idle
cpu_value,host=localhost,instance=1,type=percent,type_instance=interrupt
cpu_value,host=localhost,instance=1,type=percent,type_instance=nice
cpu_value,host=localhost,instance=1,type=percent,type_instance=softirq
cpu_value,host=localhost,instance=1,type=percent,type_instance=steal
cpu_value,host=localhost,instance=1,type=percent,type_instance=system
cpu_value,host=localhost,instance=1,type=percent,type_instance=user
cpu_value,host=localhost,instance=1,type=percent,type_instance=wait
load_longterm,host=localhost,type=load
load_midterm,host=localhost,type=load
load_shortterm,host=localhost,type=load
memory_value,host=localhost,type=memory,type_instance=buffered
memory_value,host=localhost,type=memory,type_instance=cached
memory_value,host=localhost,type=memory,type_instance=free
memory_value,host=localhost,type=memory,type_instance=slab_recl
memory_value,host=localhost,type=memory,type_instance=slab_unrecl
memory_value,host=localhost,type=memory,type_instance=used
memory_value,host=localhost,type=percent,type_instance=buffered
memory_value,host=localhost,type=percent,type_instance=cached
memory_value,host=localhost,type=percent,type_instance=free
memory_value,host=localhost,type=percent,type_instance=slab_recl
memory_value,host=localhost,type=percent,type_instance=slab_unrecl
memory_value,host=localhost,type=percent,type_instance=used
nginx_value,host=localhost,type=connections,type_instance=accepted
nginx_value,host=localhost,type=connections,type_instance=handled
nginx_value,host=localhost,type=nginx_connections,type_instance=active
nginx_value,host=localhost,type=nginx_connections,type_instance=reading
nginx_value,host=localhost,type=nginx_connections,type_instance=waiting
nginx_value,host=localhost,type=nginx_connections,type_instance=writing
nginx_value,host=localhost,type=nginx_requests
tail_value,host=localhost,instance=nginx,type=counter,type_instance=http_2xx
tail_value,host=localhost,instance=nginx,type=counter,type_instance=http_3xx
tail_value,host=localhost,instance=nginx,type=counter,type_instance=http_4xx
tail_value,host=localhost,instance=nginx,type=counter,type_instance=http_5xx
tail_value,host=localhost,instance=nginx,type=delay,type_instance=rt_seconds
Step 5: Let’s take a breath
This is what we have so far:
- The CPU % will be written to the
cpu_valuedatabase. Thetype_instancetag will contain various CPU usage categories, likesystemanduser. - The
load_shortterm,load_midtermandload_longtermtables will contain average system loads for 1 minute, 5 minutes and 15 minutes, respectively. - The
memory_valuetable will contain system RAM statistics. Thetype_instancefield contains various categories, likeusedmemory andfreememory. Thetypefield will contain whether the memory is reported asmemory, in which case its absolute memory in bytes, orpercent, in which case its a percentage of the total RAM. - The
tail_valuetable contains values from our Nginx log file, which we were reading using thetailplugin, hence the name. Thetype_instancefield contains whether its count of HTTP status codes or average request time. Once thing to note here regarding HTTP status codes. Collectd will only report total numbers up to that point in time, meaning in order to get count for a particular interval, we will have to calculate a difference with the previous value. Fortunately, InfluxDB can handle this natively using thedifference()function. - The
nginx_valuetable contains multiple values. For thetypevalue ofconnections, we havetype_instancevalues ofacceptedandhandled. For thetypevalue ofnginx_connections, we havetypevalues ofactive,reading,waiting, andwriting. We also have atypevalue ofnginx_requests, which contains the total number of requests received.
Phew. That took some doing. Once we have the above metrics, viewing them in Grafana is just a matter of spending some time creating the graphs and the queries. I’ve already covered how to add InfluxDB as a data source for Grafana, so I won’t repeat that here.
Step 6: The Grafana Dashboard
Plotting the above metrics in Grafana, and you can build something like this:
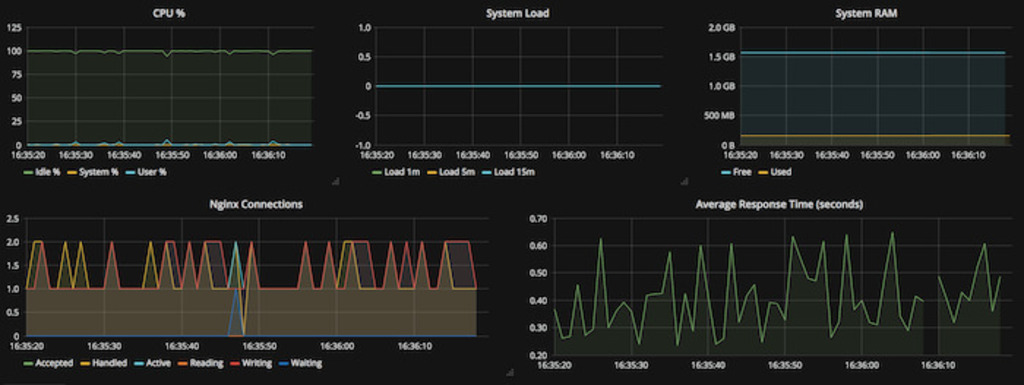
Here’s hoping this helps someone else. Thanks for sticking around.